What’s next? I want to extend the lambda function so I can ask to mirror to show me a picture of something or someone. The mirror will interpret this and get the picture for me. But first things first. I’ll be extending my lambda function to interpret slots. A slot is a sort of parameter you can pass in your Alexa intent schema. Something like “show me a picture of <abc>”. In this example <abc> is a slot of type LITERAL. Alexa will interpret you sentence and automatically assign what you said to the slot. It’s up to the lambda function to extract this info and do something with it.
Below you can find my lambda function. I added another intent at the bottom. I called it “ShowPictureIntent”, and I will be configuring it later on in my Alexa intent schema.

So what do we see here? First we check if there are slots in the intent, and if there are, if an attribute is present called “Content”. This is an arbitrary chosen attribute name. It could be anything, but I chose to call it content, because it might server another purpose in the future as well. If there’s no such thing, it will let Alexa say that it didn’t understand me.
If it did, however, the command is issued to the dynamoDB table. I created a new command called “SHOW-PICTURE”. Something my Alexa interface will have to deal with, and I put the content of the slot into a new attribute, also called “Content”.
In order to test this, I have to change the test event configuration. You can do that in the top menu.

Here you can define some JSON, and configure the correct intent, and issue a slot.

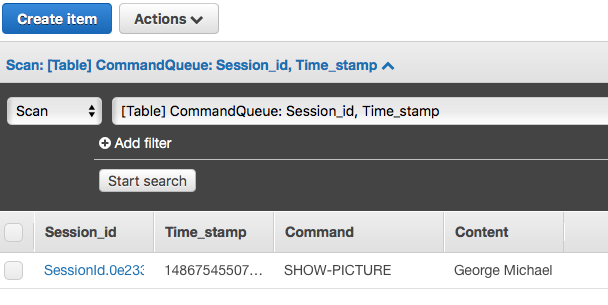
Here i’m searching for a picture of George Michael. So here’s the result of the test :

And how the command shows up in the DynamoDB table.
Now for the skill setup. We adjust the intent schema like so :

we define a new intent, with the same name as we’re handling in the function. And we define a slot, with name “Content”, just as we expect it. We want to tell the skill to expect an arbitrary string. This can be done by assigning the type “AMAZON.LITERAL”. For more info on the different slot types, you can see this documentation.
The only thing left to configure is the utterances. Like so :

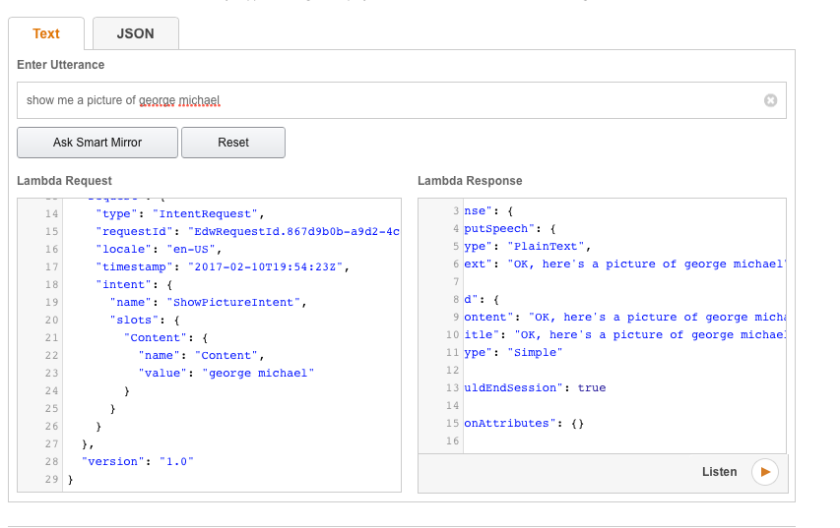
Notice how I created 2 different utterances, and the syntax for referencing the slot. Because it’s a slot of type literal, we need to tell Alexa an example of what we’re expecting. What comes before the pipe symbol is crucial here. We want it to expect a first name and a last name. Otherwise, if you just type “name” for example and if you ask it for “George Michael”, it will pass on “Michael” ; just the last word. Let’s test it :
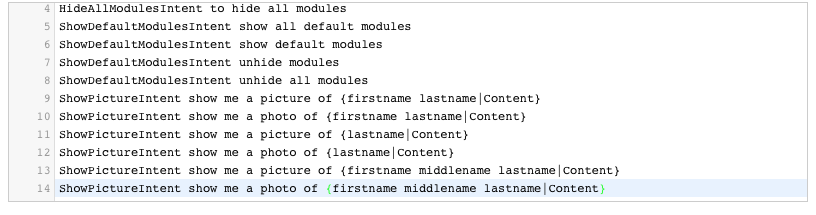
I added some some more options to be complete :

One thought on “Extending the lambda function to get user input”